Googleがリッチスニペットによる検索結果の修飾を始めたのは、2009年5月のことです。
本記事では、およそ七年にわたりリッチスニペットの表示に役立てられている構造化データについて、どのような背景を持つ概念なのか、どのように記述すればいいのかを説明致します。
構造化データとは
構造化データはなにもリッチスニペットのためだけのものではなく、本来「機械の可読性を高めよう」、という目的で利用されていた概念です。
私たち人間が言葉を読み解くときには、前後の文脈や添えられた図画を参照して意味を類推することが出来ますが、機械であるクローラにとって、そうした理解の仕方は難しいことです。
「サンドイッチ」とつづられているテキストを見たとき、その「サンドイッチ」が指すものが地名なのか人名なのか、あるいは料理なのかはクローラには判然としません。
そこで、クローラにきちんと「サンドイッチ」の意味するところを伝えるために、データをわかりやすい形式にしてあげる必要が生まれます。
決まりに則ってデータを記述し、最適な形に修飾し参照させることで、クローラがデータの持つ「意味」を正確に理解出来るようになるのです。
このクローラのために最適化されたデータこそが「構造化データ」です。
セマンティックウェブの説明
たとえば料理のレシピが載っているページから「野菜」だけを取り出したい場合には、どうすれば良いでしょうか?
まず「野菜」のリストを持ち、HTMLを分割して、一つ一つをリストと照らし合わせて……というふうに、普通の人ではまずもって難しい、技術的なやり方が必要となってきます。
キャベツを例に取ると、「植物」、「食べられるもの」、「野菜」……というように様々な「在り方」(私たちの認識の仕方、と言い変えることも出来ます)を持っていますが、生のデータ上では、「キャベツ」という言葉は幾バイトの文字列であるという以外の情報を持っていないため、私たちは「在り方」からキャベツに触れることは、大変難しいことになってしまうのです。
こうした「在り方」「私たちの認識の仕方」のことをオントロジーと呼び、これを文字列でしかないデータに括りつけて記述することで、「在り方」から対象にアプローチ出来るようにしよう、というのがW3Cが提唱したセマンティックウェブの目的の一部です。
そうした記述の仕方によってクローラの可読性が高まり、正しくデータを取得出来るようになれば、私たちもクローラを通して、柔軟にデータにアクセス出来るようになります。
機械の可読性を高めることは、私たちのためにもなるのです。
このデータ上の記述と私たちの認識をすり合わせることで「機械が私たちと同じようにデータに接触出来るような環境を整えよう」というのが、セマンティックウェブの構想であり、あらかじめメタデータ(データに付随するデータ)の形で「意味」を書き記すことによって、セマンティックなウェブを実現しよう、という構想の下で作られたのが構造化データなのです。
構造化データの記述
ひとくちに「クローラにわかりやすく記述する」といっても、どのように書けば良いのでしょうか。
たとえばサンドイッチをわかりやすく書こうとしたときには、
サンドイッチ(これはサンドイッチ伯爵のことでもケント州サンドイッチ地方のことでもなくて食べ物のサンドイッチです!)
※食べ物※サンドイッチ※たべもの※
サンドイッチ
……
というように、百人いれば百通りの書き方があることでしょう。
ですが、独自の書き方ではクローラは認識出来ません。
そのため、クローラーが認識しやすいよう、誰が書いても同じような書き方になるように、統一された規格が用意されています。
ボキャブラリーとシンタックス
構造化データをしっかり書き記すために用意されているのが「ボキャブラリー」「シンタックス」の二軸の概念です。
※ボキャブラリーとは
ボキャブラリーとはクローラが構造化データを認識するための鍵、分類で、「地名」「人名」「食べ物」……といったような、「在り方」そのもののことです。
ウェブ上にはschema.orgやData-Vocabulary.orgといったボキャブラリーのリストがあり(このリストをボキャブラリーと呼ぶこともあります)、これを参照して記述することで、データに在り方を紐付けることが出来ます。
※シンタックスとは
シンタックスとはクローラへ構造化データを渡すための書き方のことです。
MicroDataやJSON-LDといった書き方が用意されていて、このシンタックスに則ってボキャブラリーをデータに紐付けることで初めてデータの構造化が可能になります。
実際の書き方
概念的な説明をしたところで、実際に構造化データを実装してみることでボキャブラリーとシンタックスを説明致します。
Googleの構造化データテストツール(https://search.google.com/structured-data/testing-tool/u/0/?hl=ja)のスクリーンショットを交えて解説致します。
MicroDataによる記述
まず、MicroDataによる構造化データの実装について説明致します。
MicroDataによる記述は既存のHTMLのタグ内にメタデータを追記する形で行います。
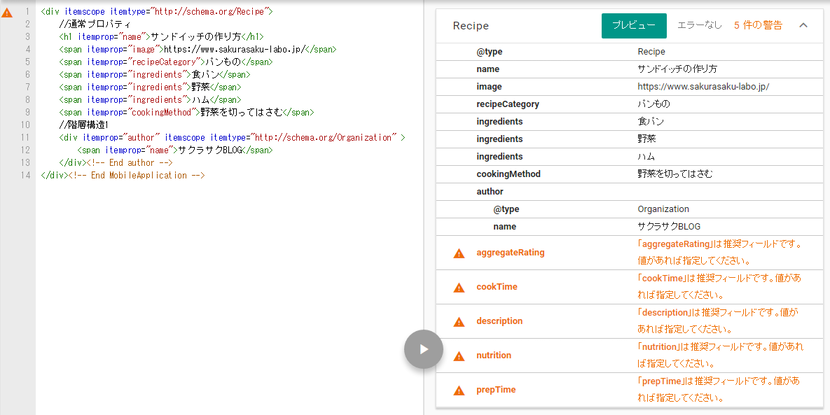
MicroDataにおいては、
の3つの要素を用いて構造化データを記述していきます。
※とは
<div >~</div> というように、を付記した任意のタグでHTMLを囲うことにより、「ここからここまでが構造化データです」と明確にクローラに伝えることが出来ます。
または入れ子構造にすることも可能で、この例ではOrganizationのを使うことで「レシピの執筆者」を記述しています。
※とは
いわゆるカテゴリのことで、「何についてのデータなのか」をここに書き記します。
に内ボキャブラリーのURLを書き記すことによって、どこどこのボキャブラリーを使用する、と明示的に宣言する必要があり、
ここではサンドイッチのレシピについて記述しているので、schema.org内のRecipeのボキャブラリーを使用しています。
※とは
属性、特性といった意味合いで、で指定したカテゴリの中のどういった特性を持つものなのか、ということを記述します。
たとえばパンや野菜やハムなどはサンドイッチの材料なので、ingredientsプロパティで材料であることをしっかり記述する必要があります。
MicroDataによる記述ではタグに直接構造化のためのマークアップを書き込むので、テキストとボキャブラリーの対応が直感的でわかりやすいというメリットがあります。
しかしHTMLの構造を変えてしまうので、DOMの取り扱いに手間が生じたり、今回のように材料が複数ある場合は複数に分けて書かなければいけないといったデメリットもあります。
JSON-LDによる記述
次に、JSON-LDによる構造化データの実装について説明致します。
JSON-LDによる記述はHTML構造とは全く関わりを持たず、任意の場所にJSON形式でつづる形で行います。
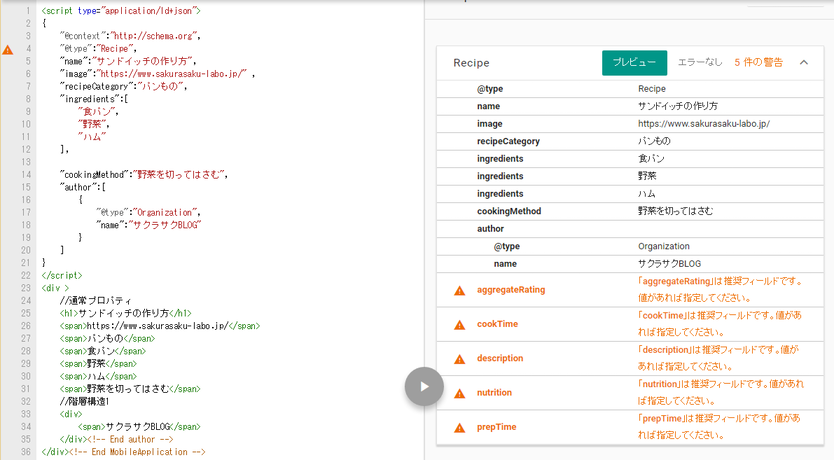
JSON-LD形式では@contextで使用するボキャブラリーのURLを指定し、@typeでカテゴリを指定します。
JSON-LD形式ではHTMLの構造を全く崩すことなく記述出来、配列の形にすることによって同じプロパティのものを一度に同時に記述出来る等のメリットがあります。
デメリットとしてはHTMLとは別に1から書くので労力がかかる、といった点があります。
どちらの方式を使用しても、正しく記述出来ていれば問題なくクローラは構造化データを認識します。
自分で構造化データを記述するのは難しい、といった方に向けて、構造化データマークアップ支援ツールといったものも公開されています。
https://www.google.com/webmasters/markup-helper/u/0/
まとめ
以上、構造化データについて説明致しました。
リッチスニペットの表示に必須の構造化データ。
今後「クローラーが利用しやすいデータで作られたウェブ」が作り上げられていけば、リッチスニペット以外にも様々な利用の仕方が生まれることも考えられます。
クローラビリティを考えて、人にもクローラにも優しいウェブを作りましょう。
SEOの最新情報を手に入れることで、SEO施策を強化しましょう
本記事でご紹介した構造化データは現在JSON-LDが主流となるなど、記事執筆時点と大きく状況が変わってきています。
また現在のSERPsでは構造化データによる多様なリッチスニペットが表示されるようになっており、検索結果からの流入を増やす観点では対応が必須と言えます。
こうしたSEOの最新情報をサクラサクラボでは無料メルマガで発信中!
どなたでもお名前とメールアドレスのみで簡単に登録がいただけますので是非ご活用を!
↓↓↓メルマガ登録はコチラ↓↓↓







